Speculative decoding, production numbers
EAGLE 3.1 benchmarks on Kimi-K2.6-NVFP4 (vLLM TP=4, GB200, SPEED-Bench coding)
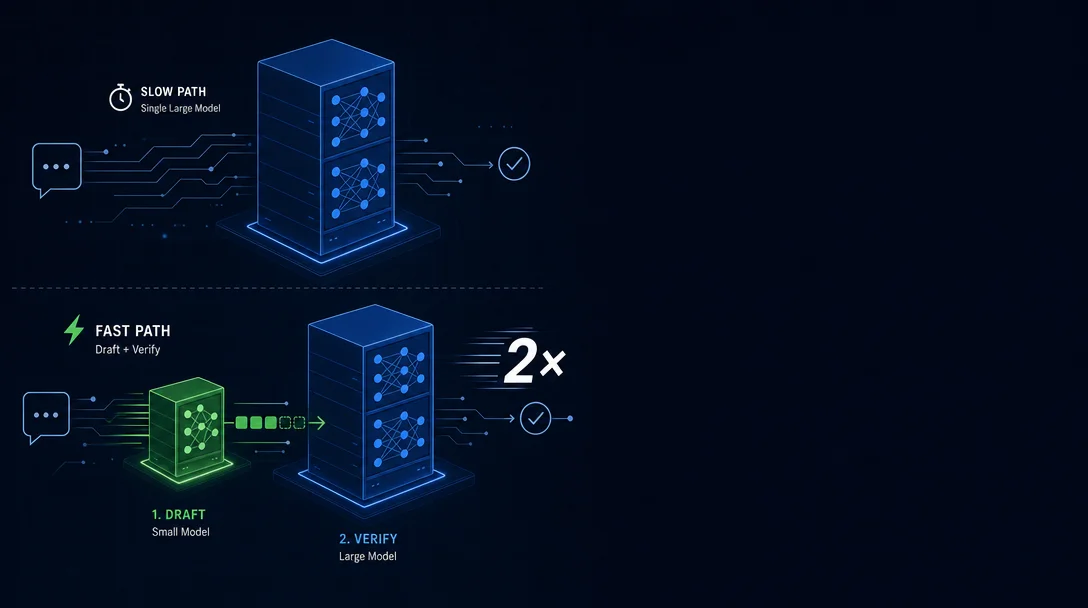
Speculative decoding has been in vLLM for a year but disabled in production because of attention drift. EAGLE 3.1, released May 26, fixes the root cause with two architectural changes — and delivers a verified 2× throughput gain with one JSON config flag. Here's what changed, why it matters, and when to turn it on.

"Speculative decoding has a marketing problem. The pitch sounds too good to be true: run a small draft model alongside your large model, guess multiple tokens ahead, verify in parallel, and get 1.5–3× throughput with zero quality loss." 2
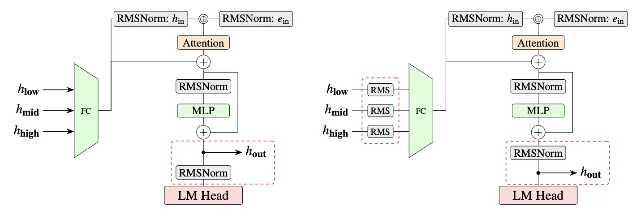
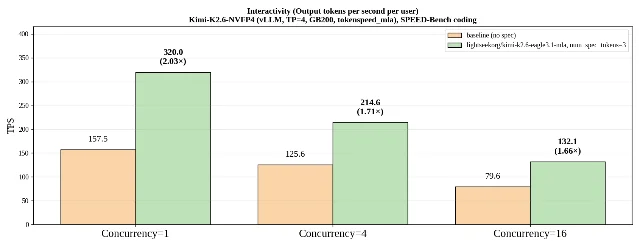
lightseekorg/kimi-k2.6-eagle3.1-mla (3B, BF16) — is on HuggingFace. 4vllm serve nvidia/Kimi-K2.6-NVFP4 \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}'method field stays eagle3 — fully backward-compatible. Add --enable-metrics to expose a Prometheus endpoint; monitor acceptance_rate in production to confirm the workload is compatible within minutes.
Add more perspectives or context around this Post.